1. Background
The objective of this paper is three-fold: to improve the quality of student data, to predict student academic performance and cluster groups of students with similar learning styles, using data mining techniques such as ensemble classification, anomaly detection and clustering. Ensemble methods have been called the most influential development in data mining and machine learning in the past decade. They combine multiple models usually producing an accurate model than the best of its individual components.
2. Our Contributions
1. To use ensemble filtering on student data to improve the quality of the data, by eliminating mislabeled
class noise.
2. To use ensemble classification to create a more accurate prediction of student performance in two
different environments: high school and first year college data.
3. To use bootstrap averaged k-means clustering to identify groups of students with similar learning
styles
3. Methodology
a. Ensemble Noise Filtering
We focus on improving the quality of student academic
training data by identifying and eliminating mislabeled instances by using multiple classifiers. An ensemble
classifier detects noisy instances by constructing a set of classifiers (base level detectors).

b. Bootstrapped averaging using k-means clustering
Our approach builds multiple models by creating
small bootstrap samples of the training set and building a model from each, but rather than aggregating
like bagging, we average similar cluster centers to produce a single model that contains k clusters. To
test the effectiveness of bootstrap averaging, we apply clustering in finding representative clusters of
the population.

4. Dataset
a. Student Performance Dataset (UCI)
This dataset is based on a study of data collected during the 2005-2006 school year from two public schools, from the Alentejo region of Portugal
b. First year college student performance dataset
First year Computer Systems Technology students from the New York City College of Technology (CUNY) enrolled in 6 different semesters (Fall 2013, Fall 2014, Fall 2015 Spring 2013, Spring 2014 and Spring 2015) taking an introductory computer systems course was used for this study
5. Our Results
a. Accuracy

b. Clustering
Before Clustering
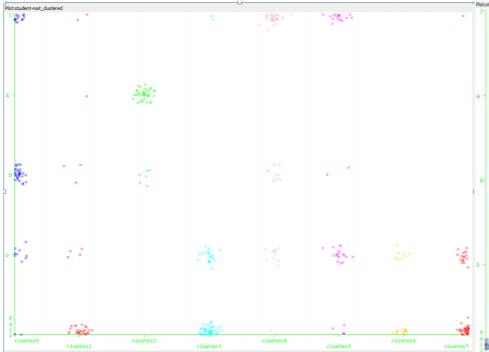
After filtering the noisy data on the training set, we identify and cluster groups of students in the test set using k-means bootstrapped averaging. Once the instances are filtered, well defined clusters can be identified as shown
After Clustering

This project has been published in a journal! Check it out here